› Forums › Tenchi Muyo! Discussion › Translation Zone › KanjiOCR Text Ripper
- This topic is empty.
- Post
-
- January 21, 2012 at 3:38 PM
KanjiOCR is a abandonware program for optical character recognition, or ripping text off Japanese scans. Works better than ReadIris and most other non-Japanese made programs
I’ve seen thus far.
You have to feed it 1-bit bitmap images (rather ugly after conversion) or formatted TIF
images (somewhat better).
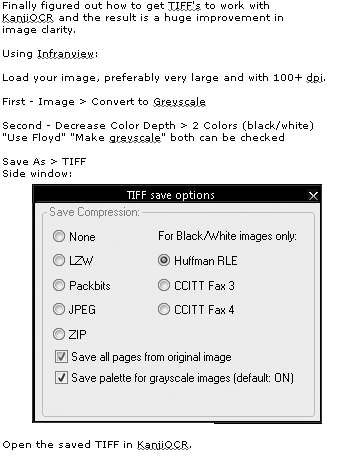
http://i32.photobucket.com/albums/d1/GuardianZinv/Translation/TiffOptions.gif " /> Infranview is a free image editor that doesn’t do a half bad job. Formatting for TIF in Photoshop
CS1 seems impossible. Not sure about GIMP.
Some general thoughts:
Larger the image the better, so the larger source you can get, the clearer things will come out.
Pretty much you’ll need to make the files into 1 bit bitmaps using infranview. Image > decrease color depth> greyscale and 1 BPP.
Save as a BMP.
For KanjiOCR – I think you only need the japanese font support.
So like if you can go to a JP site amazon.co.jp for example… and see the JP characters you should be fine.
If you’re on Win 7, might have to run it in compatibility mode.
Also – when drawing the OCR boxes in KOCR… take the lines
(vertical or horizontal) one at a time in strips. Not paragraphs or
multiple lines together.
It seems to me doing both horizontal and vertical lines together (there’s a button for mixed versus separate) comes out a little worse
than if you did one pass of horizontals and another for vertical… but I don’t have any hard data to back that up.
Once you’ve got it recognized, save as a unicode txt file.
This is important – otherwise you won’t get any visible output.
Proofread the characters you get in the txt with the original image. Do they match?
If not you can try to crop and enlarge the missing/wrong characters (clean them up graphically)
and OCR them again… sometimes it works. Otherwise what I do is build a library of characters
I can browse through in other unicode files to see if I can copy and paste it over to replace the
offending item. Sometimes I can find the character floating around on Japanese sites.
Also here’s 3 little helpers for proofreading:
http://chasen.org/~taku/software/ajax/hwr/ Draw the character and it’ll try to match it with a symbol.
http://learnthekana.com/the-hiragana-chart/ http://learnthekana.com/the-katakana-chart/ Quite invaluable charts to have, I have 2 different paper versions of the H & K charts so
I can compare with. You can copy the symbols out and paste into the unicode file to replace missing or wrong characters.
Protip – if the unicode txt opens in wordpad, change the font to about 26pt or something large so you can actually read the characters.
When you’re finished run the text through each of the translators and you should get something semi legible.
Post it up to the forum or try to collaborate with others to get a decent translation.
- The topic ‘KanjiOCR Text Ripper’ is closed to new replies.